dj-woo.github.io
JEMC
리뷰할 paper는 Learning Joint Embedding with Multimodal Cues for Cross-Modal Video-Text Retrieval 입니다.
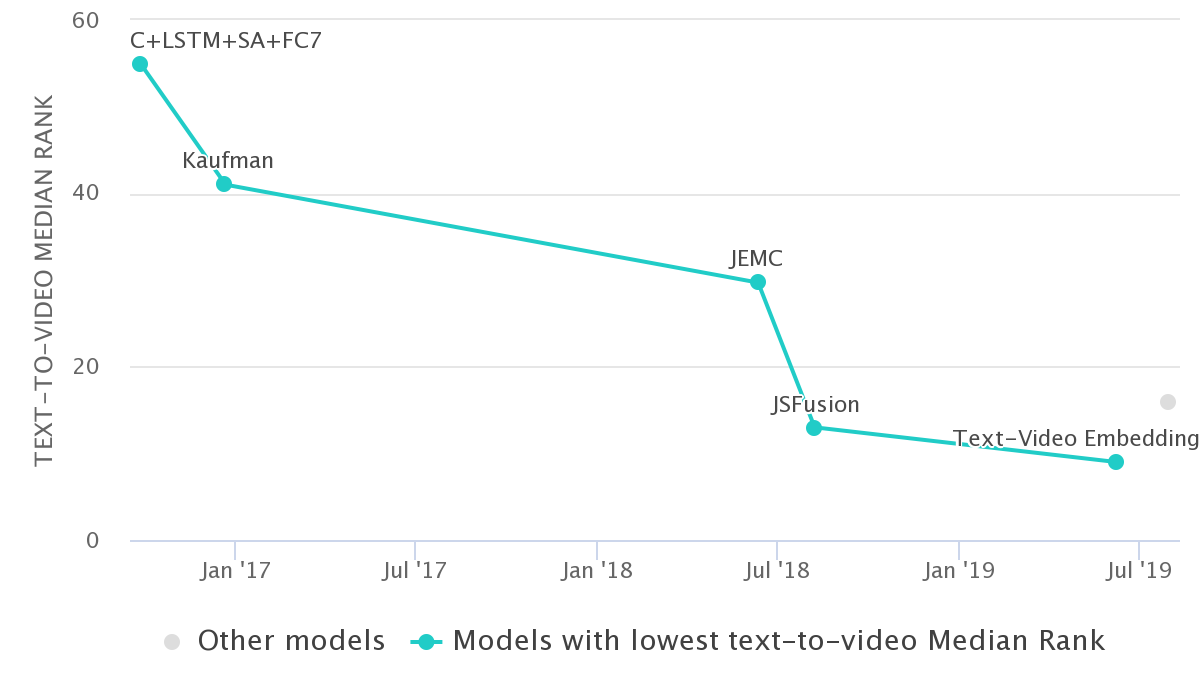
논문에서 제안한 JEMC는 Video Retrieval on MSR-VTT에 현제 4위에 rank되어 있습니다.
1. INTRODUCTION
cross-modal video-text retrieval task에서, 학습은 video feature와 text feature를 하나의 space에 project하는 방식으로 이루어 집니다. 이때, video에 포함된 다양한 feature (actions , objects, place, time)들을 얼마나 잘 활용하는지가 모델의 성능을 결정하는 중요한 요소입니다. video에서 objects(ResNet), activities(I3D) feature를 추출하는 방법들은 많이 개발되었습니다.
본 논문에서는 이러한 feature들을 효율적으로 fustion하는 방법을 제안합니다. 본 논문에서 제안하는 방법의 contribution은 크게 아래 2가지 입니다.
- acttion, object, text, audio features를 fusion할 수 있는 architecture
- hinge based triplet loss를 기반으로한, ranking loss function
paper: Contributions: The main contributions of this work can be summarized as follows.
• The success of video-text retrieval depends on more robust video understanding. This paper studies how to achieve the goal by utilizing multi-modal features from a video (different visual features and audio inputs.).
• Our proposed framework uses action, object, text and audio features by a fusion strategy for efficient retrieval. We also present a modified pairwise loss to better learn the joint embedding.
• We demonstrate a clear improvement over the state-of-the-art methods in the video to text retrieval tasks with the MSR-VTT dataset [35] and MSVD dataset [4].
2. REALTED WORK
Image-Text Retirevel
주로 loss function에 대한 related work을 분석하였습니다.
서로 다른 feature들을 하나의 space로 project하도록 학습하기 위한 방법으로, hinge based triplet loss가 많이 사용되었습니다.
여기에 추가적으로 아래와 같은 방법이 사용되었습니다.
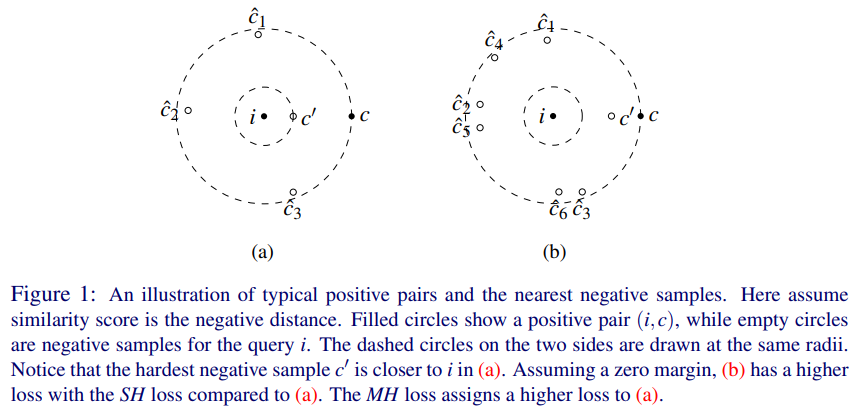
triplet loss의 개념과 closest negative sample만을 사용하는 VSEPP[2]가 어떻게 성능을 개선할 수 있는 지는 아래 그림을 통해 알 수 있습니다.
Video-Text Retirevel
이전 방법들에서는 Video에서 추출할 수 있는 여러 feature들이 제한 적으로 사용되었다는 내용이 주로 나옵니다.
3. APPROACH
본 논문에서 제안하는 전체 architecture는 아래 그림과 같습니다.
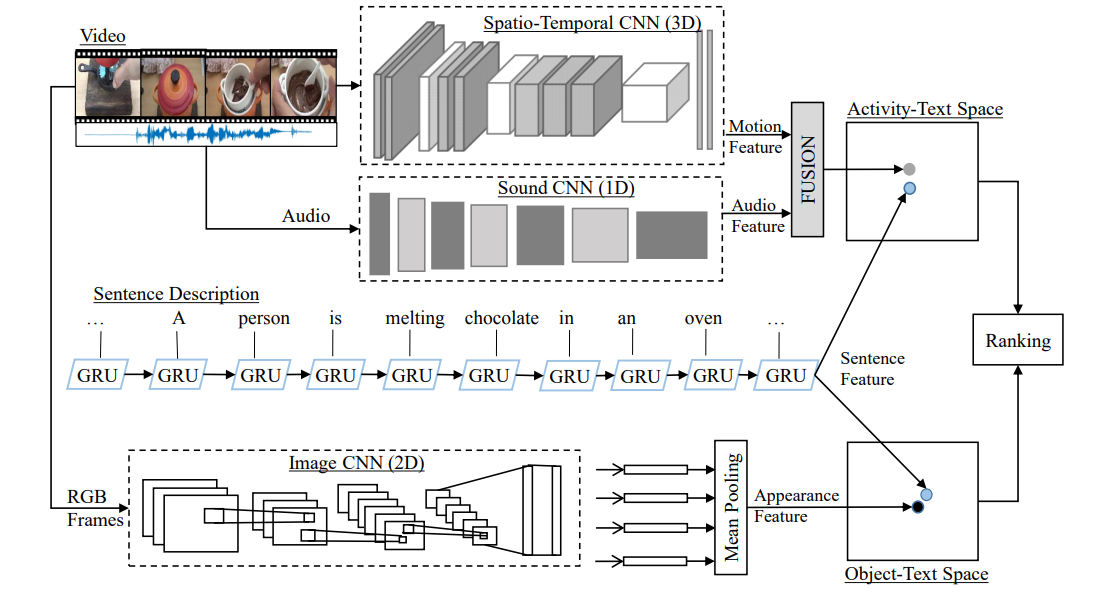
input (video, text)에서 text, activity, object, audio feature를 각각의 model을 사용해서 추출합니다. 추출된 feature들을 2개의 joint space(ObjectText Space, Activity-Text Space)에 project하여, sentence와 video의 similarity score를 구합니다. 이때, 각 joint space는 제안하는 Ranking loss를 사용하여 학습합니다.
- ObjectText Space = text(GRU) + object(Resnet152)
- Activity-Text Space = text(GRU) + [activity(I3D), audio feature(Sound Net)]
각 joint space에서 구해진 similarity scores 더해져 최종 ranking을 구합니다.\
3.1 Input Feature Representation
각 feature를 추출하는 방법은 아래와 같습니다.
- Text Feature:
- model: GRU
- input: word embedding (D=300)
- end-to-end 학습
- Object Feature:
- model: Resnet152
- input: image (224 x 224)
- embedding size = 2048
- use pre-trained model (ImageNet dataset)
- Activity Feature:
- model: I3D
- input: use 16 frame images
- embedding size = 1024
- use pre-trained model (RGB-I3D model)
- Audio Feature:
- model: SoundNet CNN
- embedding size = 1024
- use pre-trained model
3.2 Learning Embedding & 3.3 Proposed Ranking Loss
joint space로의 project를 위해 사용한, ranking loss function에 대해서 설명하는 session입니다.
수식에서 나오는 변수들은
$v$: video feature를 joint space에 embedding한 vectore$t$: text feature를 joint space에 embedding한 vectore$v^-, t^-$: negarive sample에서 non-matching vectore$s(v,t)$: positive sample의 score$s(v,t^-) or s(v^-,t)$: negative sample의 score$\hat{v}, \hat{t}$: hardest negative sample
hinge based triplet loss을 사용한 수식은 아래와 같습니다. 여기서 $[f]_+ = max(f,0)$ 입니다.
모든 negative samples에 대해 optimize를 진행하므로, local minimun에 빠지기 쉽습니다. $$ \min_θ \sum_v \sum_{t^-} [α − S(v, t) + S(v, t^-)]_+ + \sum_t \sum_{v^−} [α − S(t, v) + S(t, v^-)]_+\\ $$ closest negative sample만을 사용하는 VSEPP[2]의 수식은 아래와 같습니다. negative sample들중 가장 similarity가 높은 sample에 대해서만 계산합니다. $$ \min_θ \sum_v [α − S(v, t) + S(v, \hat{t})]_+ + \sum_t [α − S(t, v) + S(t, \hat{v})]_+\\ $$ 본 논문에서는 VSEPP에 weighted ranking을 결합한 방식을 제안하였습니다. 수식은 아래와 같습니다. $$ \min_θ \sum_v L(r_v) [α − S(v, t) + S(v, \hat{t})]_+ + \sum_t L(r_t) [α − S(t, v) + S(t, \hat{v})]_+\\ L(r_v)=(1 + 1/(N-r_v+1))\\ r_v = rank\ of\ (v,t) $$
3.4 Matching and Ranking
총 ranking은 Object-Text space와 Activity-Text space의 similirity score 합으로 결정됩니다.
4. EXPERIMENTS
실험에는 Video to Text(MSR-VTT) dataset과 Microsoft Video Description(MSVD) dataset이 사용되었습니다.
- hyperparameter
- batch size = 128
- learning rate = 0.002 (/10 per 15 epochs)
- ADAM optimizer
- empirically choose margine α = 0.2
- Evaluated on the validation set after every epoch. The model with the best sum of recalls on the validation set is chosen finally.
Table1는 MSR-VTT Dataset를 사용한 결과를 보여 줍니다. Ablation Studies도 같이 나와 있습니다. 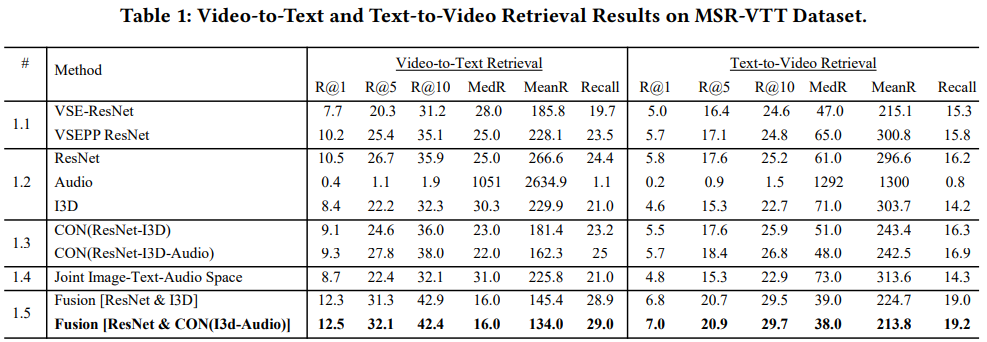
실험 설명
- #1.1 Performance of loss function
- #1.2 Performance of different features
- #1.3 Performance of direct concatenation of different video features
- #1.4 Performance of one shared aligned space (using image-text and image-sound pairs loss)
- #1.5 Performance of two video-text spaces
결과 분석
- Loss Function:
- 전반적으로 제안한 weighted ranking loss > VSEPP > VSE의 성능을 보입니다.
- MeanRank에서 VSE가 성능이 잘나오기도 하는데요. 이는 VSE가 모든 sample을 optimize하려는 특징이 있기 때문이라고 볼 수 있습니다.
- Video Features:
- Audio 단독으로 사용시 매우 낮은 performance를 보입니다.
- Audio를 다른 feature와 같이 사용하면 성능에 유의미한 차이를 보입니다.
- Feature Concatenation for Representing Video:
- multi video feature들의 단순한 concat은 오히려 single feature를 사용할 때보다 안 좋은 결과를 보여줍니다.
- 이를 통해, 서로 다른 성질의 feature를 concate하는 것은 오히려 안 좋다는 것을 알 수 있습니다.
- Learning a Shared Space across Image, Text and Audio:
- 단순 concat이 아닌 pair wise loss를 사용하여, 하나의 space에 project하여도 안 좋은 결과를 보여줍니다.
- 3개의 feature를 하나의 space에 project하는 방식이 model의 flexibility를 더 줄 수 있지만, 결과적으로 더 복잡한 task가 되어 성능 최적화를 위한 좋은 방법은 아니라고 결론짓습니다.
- Fusion:
- Audio feature를 추가로 사용할 경우, 유의미한 성능개선을 보입니다.
- 하지만 main feature라고 볼 수는 없기 때문에, model에서 별도의 space를 부여하지는 않았습니다.
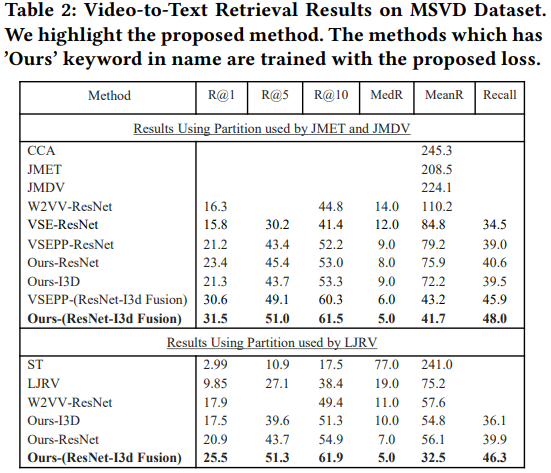
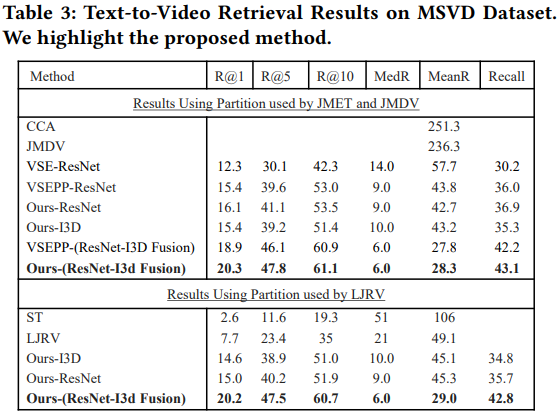
Table2,3은 MSVD Dataset을 사용한 결과입니다. MSVD Dataset은 mute dataset입니다. 결론적으로 제안하는 방법이 가장 좋은 성능을 보여줍니다.
CONCLUSIONS
본 논문에서는 cross-modal video-text retrivel 을 위한, 여러 video feature들과 audio feature를 joint embedding하는 방법을 제안하였습니다. 또한 효율적인 학습을 위하여, loss function에 weighted ranking을 결합한 방법을 제안하였습니다. 이를 통해서, 2가지 dataset에서 가장 좋은 성능을 보였습니다.