dj-woo.github.io
ImageBERT
리뷰할 paper는 ImageBERT: Cross-modal Pre-training with Large-scale Weak-supervised Image-Text Data 입니다.
순서는 논문과 동일한 순서로 되어 있습니다.
Key word
- Large Data Set
- One Transformer
- Multi-stage Pre-training + 4 tasks
1 Introduction
Text-Image Retrieval, Visual Question Answering(VQA), Visual Commonsense Reasoning(VCR)등 image와 text를 둘다 처리하는 task에 관심이 많아 지고 있는데요.
NLP에서 성공을 보인, pre-training을 활용한 방법을 language + vision cross modal task에도 적용하고 하는 노력이 있었습니다.
이 논문에서 이러한 cross-modal pre-training 방법들을 비교하고, 자신들이 제안한 방법들을 소개합니다.
Transformer가 제안된 후, 많은 논문들이 이를 활용하여 cross-modal 문제를 풀고자 하였습니다. 이들을 중심으로 related work을 분석하였습니다.
- Model Architecture
- language와 vision에 별도의 transformer를 적용후, 이에 cross-modal transformer를 추가하는 방법: ViLBERT, LXMERT등
- image와 sentence를 하나로 concat 시킨 후, 하나의 transfomer에 넣어서 처리하는 방법: VisualBERT, B2T2, Unicoder-VL, VL-BERT, Unified VLP, UNITER등
- 두 방법 중 어느 방법이 좋다고 말 할 수 없지만, 본 논문에서는 하나의 transfomer를 사용합니다.
- Image visual tokens
- 많은 방법에서 regions of interest(RoI)를 word의 token처럼 사용합니다.
- VL-BERT에서는 RoI를 구하는 detection model까지 같이 학습을 하였습니다. 보통 학습된 model을 사용합니다. 또한 global image feature도 token으로 추가하였습니다.
- Pre-train data
- 기존에 많이 상용되는 data-set은 Conceptual Captions(3M)과 SBU Captions(1M)이 있지만, NLP에서 사용하는 방대한 data-set에 비하면, 만족할 만한 data-set을 얻기 어렵습니다.
3 Large-Scale Week-supervised Image-Text Data Collection
NLP의 경우, wiki와 같이 매우 방대한 data-set(wiki, book, …)을 얻을 수 있지만, cross-modal에서는 이러한 방대한 data-set을 얻기 어렵습니다.
많이 사용하는 data-set으로 CC(3M), SBU(1M)가 있지만, 충분하다고 볼 수 없습니다.
이를 보완하기 위해서, 논문에서는 web-site에서 LAIT(Large-scale weAk-supervised Image-Text)(10M)를 만들었습니다. LAIT를 만드는 방법은 아래 그림과 같이 5단계로 이루어 집니다.
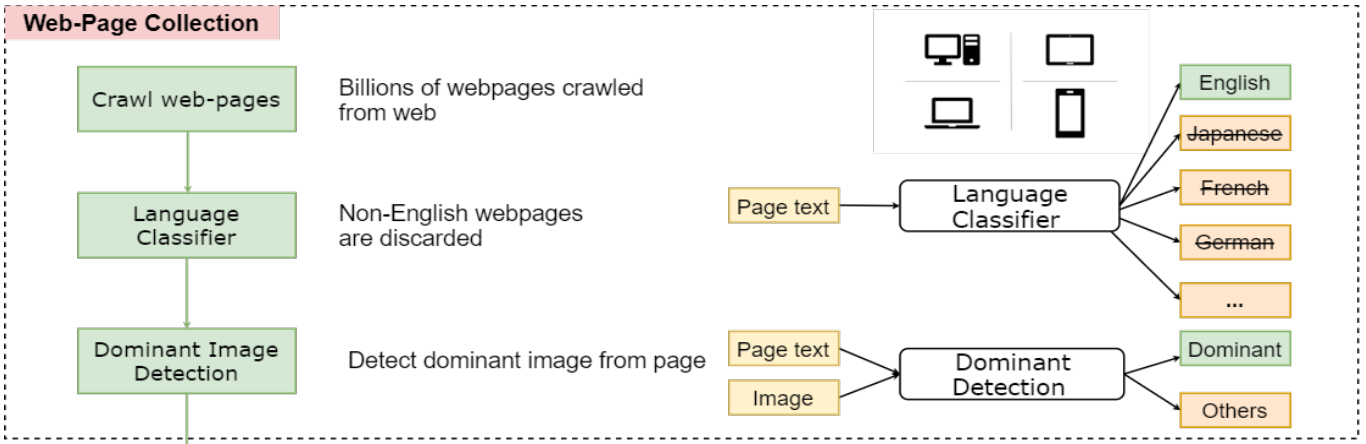
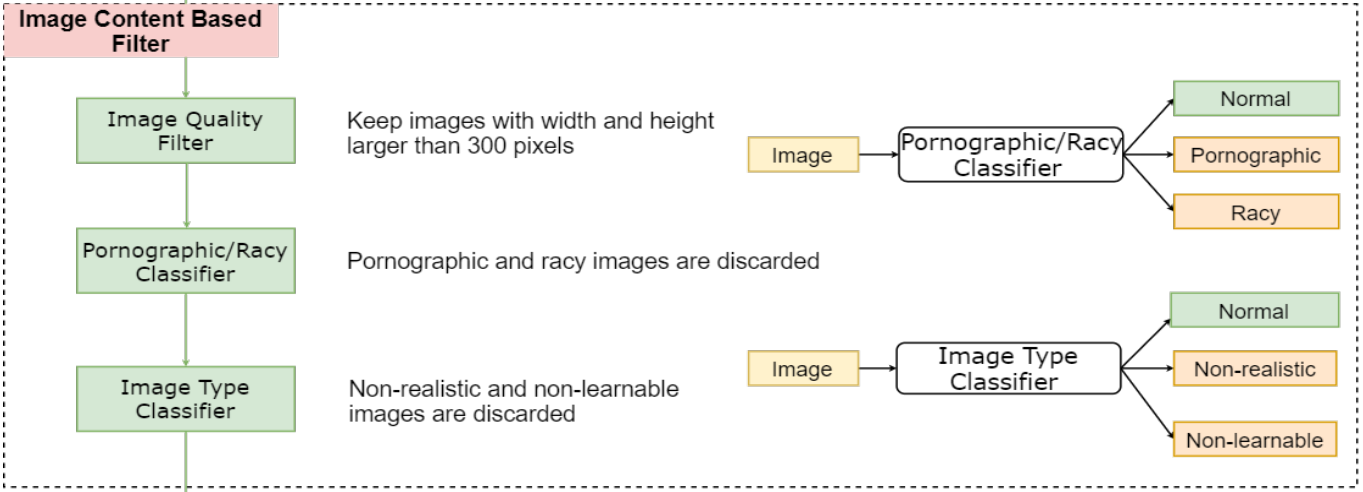

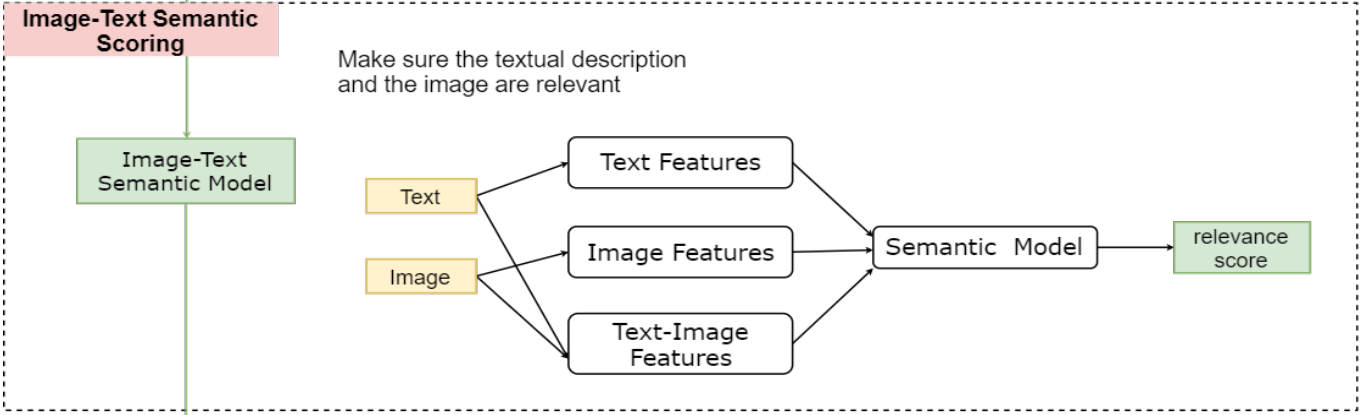

[Example of LAIT] 
[Discarded Example of LAIT] 
4 ImageBERT Model
ImageBERT model 구조는 아래와 같습니다. 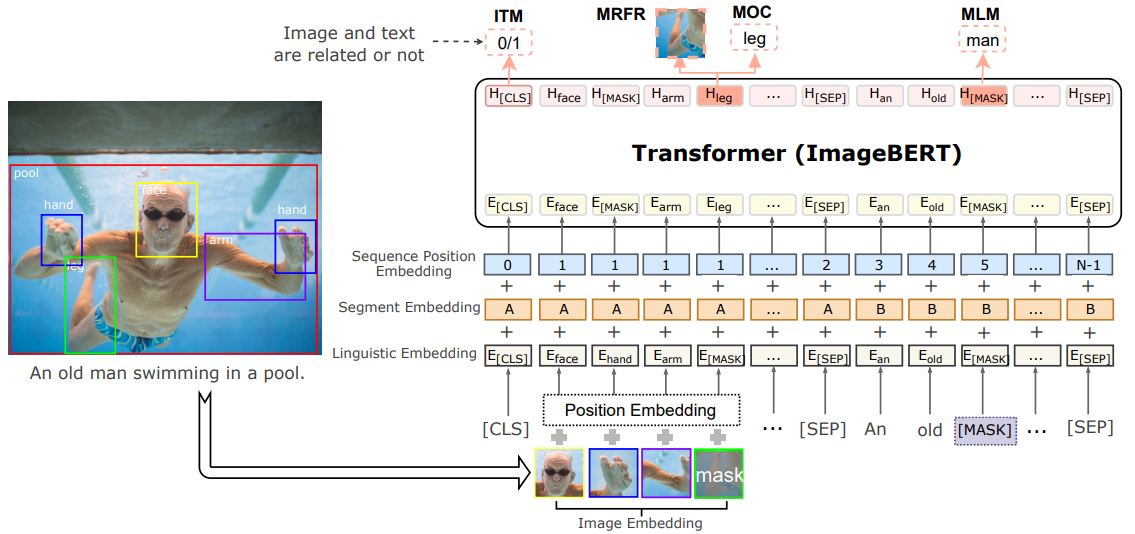 BERT와 비슷하게 Transformer를 basic structure로 사용하였으면, visual token과 textual token을 input으로 사용하였습니다.
BERT와 비슷하게 Transformer를 basic structure로 사용하였으면, visual token과 textual token을 input으로 사용하였습니다.
visual token과 textual token은 서로 다른 방법으로 embedding된 후, BERT로 들어갑니다.
4.1 Embedding Modelins
- textual token을 만들기 위해서, BERT와 동일한 WorlPiece[2]를 사용 합니다.
- visual token을 생성하기 위해서, Faster-RCNN[3]를 사용하여 RoI 추출합니다. 이때 생성되는 feature와 location 정보를 사용하여 visual token을 embedding합니다. 이때, 각각의 embedding layer는 Transformer의 hidden size와 동일한 size로 각 vector를 project합니다.
$ c^{(i)} = (\frac{x_{tl}}{W},\frac{y_{tl}}{H},\frac{x_{br}}{W},\frac{y_{br}}{H},\frac{(x_{br}-x_{tl})(y_{br}-y_{tl})}{WH})\\ r^{(i)} = extracted\ features\ of\ the\ i_{th}\ RoI\\ v^{(i)} = ImageEmbed(r^{(i)})\\ s^{(i)} = SegmentEmbed(i)\\ p^{(i)}_{img} = PositionEmbed(c^{(i)})\\ p^{(i)}_{seq} = PositionEmbed(i)\\ e^{(i)} = LN(v^{(i)} + s^{(i)} + p^{(i)}_{img} + p^{(i)}_{seq}) $ - sequence position embedding의 경우, visual token에는 dummy vector가 적용되면, textual token에는 순서에 따라 vector가 배치됩니다.
- segment embedding의 경우, 서로 다른 modality를 표현하는 용도로 사용됩니다.
4.2 Multi-stage Pre-training
data-set의 출처가 다르고, quality & noise distribution이 서로 다르기 때문에, 아래와 같은 multi-stage pre-training을 사용하였습니다.
학습의 순서는 large-scale out-of-domain data-set으로 먼저 학습하고, 이후에 점차 small scale in-domain data-set으로 학습을 진행합니다.
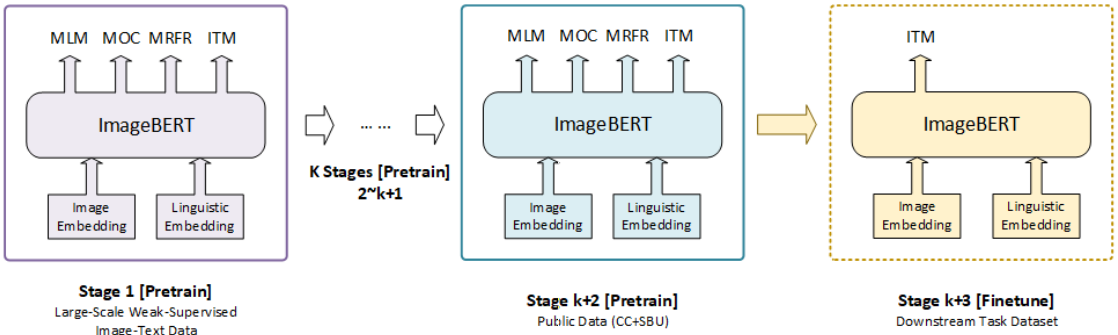
4.3 Pre-training tasks
linguistic information과 visual content를 학습하기 위하여, 4가지 task를 사용하였습니다.
- Masked Language Modeling (MLM): Bert에서 사용한 MLM와 동일한 task
- masked randomly with a probability of 15%
- replaced with a special token [MASK](80%), a random token(10%), remains unchanged(10%)
- using the negative log-likelihood
$$ L_{MLM}(θ) = −E_{(v,w)∼D} log Pθ(w_{mT}|w_{\mT}, v) $$
- Masked Object Classification (MOC)
- masked randomly with a probability of 15%
- replaced with a zero out the masked token(90%), keep the original token(10%)
- add a fully-connected layer to predict the correct label from K object classes
- using the cross-entropy(CE) loss
- Faster R-CNN model as ground truth label:
$l_{θ}(v^{(i)}_{mI})$ - the output vector corresponding to the masked token:
$f_{θ}(v^{(i)}_{mI})$$$ L_{MOC} (θ) = −E_{(v,w)∼D}{\sum^{M−1}_{i=0}CE(l_{θ}(v^{(i)}_{mI}), f_{θ}(v^{(i)}_{mI}))} $$
- Faster R-CNN model as ground truth label:
- Masked Region Feature Regression (MRFR)
- This task aims to regress the embedding feature of each masked object
- add a fully-connected layer on top of the output feature vector to make same dimension
- using the L2 loss
- Faster R-CNN model as ground truth feature:
$ r_{θ}(v^{(i)}_{mI}) $ - the output feature corresponding to the masked token:
$ h_{θ}(v^{(i)}_{mI} $$$ L_{MRFR} (θ) = −E_{(v,w)∼D}{\sum^{M−1}_{i=0}\lVert h_{θ}(v^{(i)}_{mI}) - r_{θ}(v^{(i)}_{mI})} \rVert_2^2 $$
- Faster R-CNN model as ground truth feature:
- Image Text Matching (ITM)
- This task aims to learn the image-text alignment
- Negative training data
- randomly sample negative sentences for each image
- randomly sample negative images for each sentence
- addy a fully-connected layer on top to obtain the image-text similarity score:
$s_θ(v, w)$ - using binary classification loss
- the ground truth label:
$y ∈ {0, 1}$$$ L_{ITM}(θ) = −E_{(v,w)∼D}[y \log s_θ(v, w) + (1 − y) \log (1 − s_θ(v, w))] $$
- the ground truth label:
4.4 Fine-tuning tasks
Fine-tuning은 MSCOCO and Flickr30k data-set으로 진행하였으며, input sequence는 pre-training과 동일합니다. Fine-tuning과정에서는 mask를 사용한 task들은 사용하지 않고, ITM만 사용하였습니다. 3가지 loss를 사용하여 실험을 진행하였습니다.
- Binary classification Loss
$ L_{BCE}(θ) = −E_{(v,w)}[y \log c_θ(t_{(v,w)}) + (1 − y) \log (1 − c_θ(t_{(v,w)}))] $ - Multi-class Classification Loss
$ L_{CE}(θ) = −E^{(j)}_{(v,w)}{\sum^{P-1}_{j=0}}CE(s(t^{(j)}_{(v,w)}), l^{(j)}_{(v,w)}) $ - Triplet Loss
$ L_{Triplet}(θ) = −E^{(j)}_{(v,w)}{\sum_(n^-∈N)} \max [ 0, s(t_{(v,w)^+} ), s(n^-_h)] $
5 Experiments
- Transformer: a 12-layer with 768 hidden units, 3072 intermediate units, and 12 attention heads
- Dropout probability to 0.1
- Use GELU as activation function
- The max length of our input sequence is fixed to 144, 100 visual tokens + other linguistic tokens and special tokens
- Use a Faster RCNN model pre-trained on Visual Genome dataset with 1600 categories
- Pre-training:
- data-set
- 1-stage: Use the LAIT(10M), with parameter initialized from the BERT-base model
- 2-stage: Use pre-training on public datasets: CC(3M), SBU(1M)
- hyperparamter
- batch size = 48
- learning rate = 1e-4 with Adam optimizer
- 17 epochs using 4 V100 GPUs
- tasks
- Use conditional mask in MLM, MOC and MRFR tasks
- Only calculate the masked loss when the input pair is a positive sample
- data-set
- Fine-tuning
- data-set
- Use Flickr30k and MSCOCO
- hyperparameter
- batch size = 24
- learning rate = 5e-5
- 130 epochs using 4 V100 GPUs
- tasks
- Only use ITM
- data-set
5.1 Evaluation for the Pre-trained Model
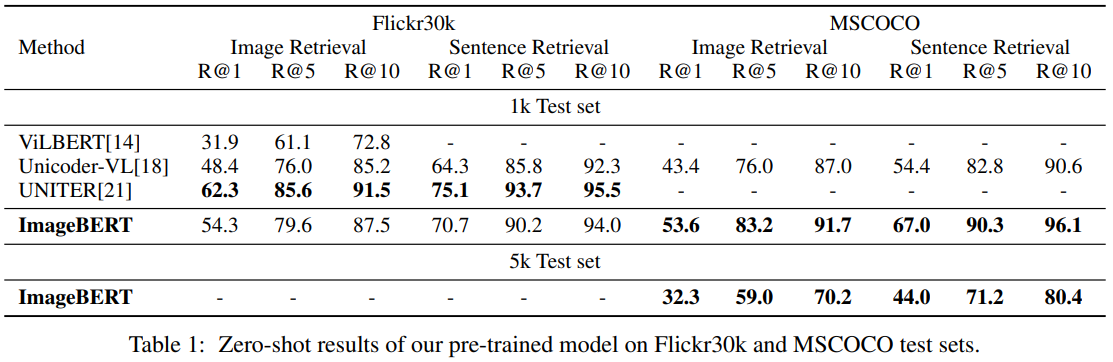
Zero-shot result of pre-train model: 1-stage pre-training을 사용한 방법과 비교하여, comparable results를 보입니다. 추가적으로, fine-tuning에서는 더 좋은 결과를 보여주기 때문에, multi-stage pre-training이 single-stage pre-training 보다 useful한 지식을 학습 한다고 되어 있습니다.
our multi-stage pre-training strategy learns more useful knowledge during pre-training, and can consequently contribute to the fine-tuning stage on the downstream tasks.
5.2 Evaluation for the Fine-tuned Model
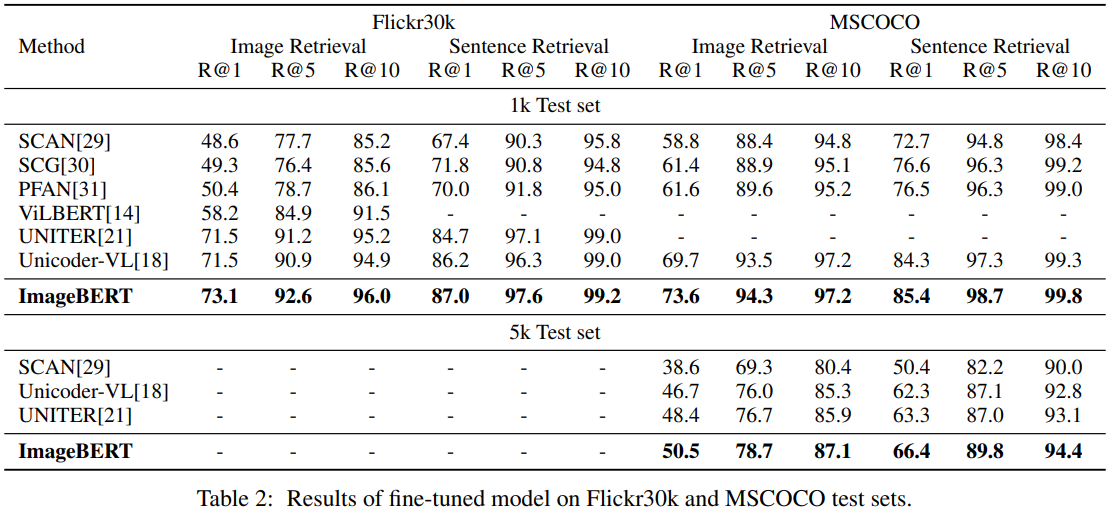
Flickr30k와 MSCOCO에서 모두 state-of-the-art를 달성하였습니다. pre-training에서 quality & noise distribution가 다른 data-set을 사용할 경우, data-set을 나누어 학습하는게 하나로 학습하는 것보다 좋다는 것을 알 수 있습니다.
5.3 Ablation Studies
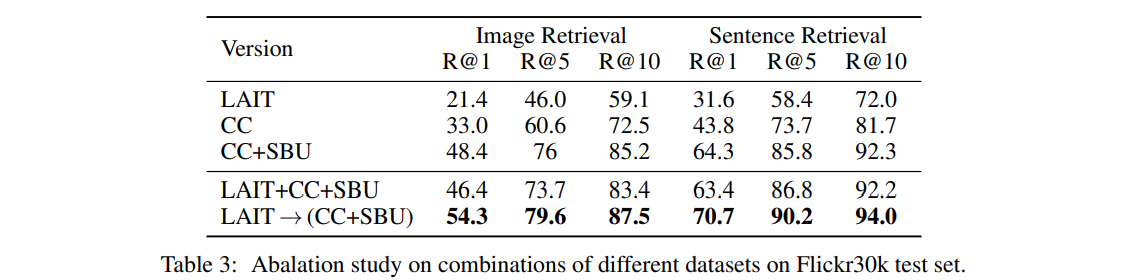
Pre-train dataset: LAIT, CC, SBU를 조합한 test들에서, 제안한 multi-stage pre-trining이 가장 좋은 성능을 보였습니다.
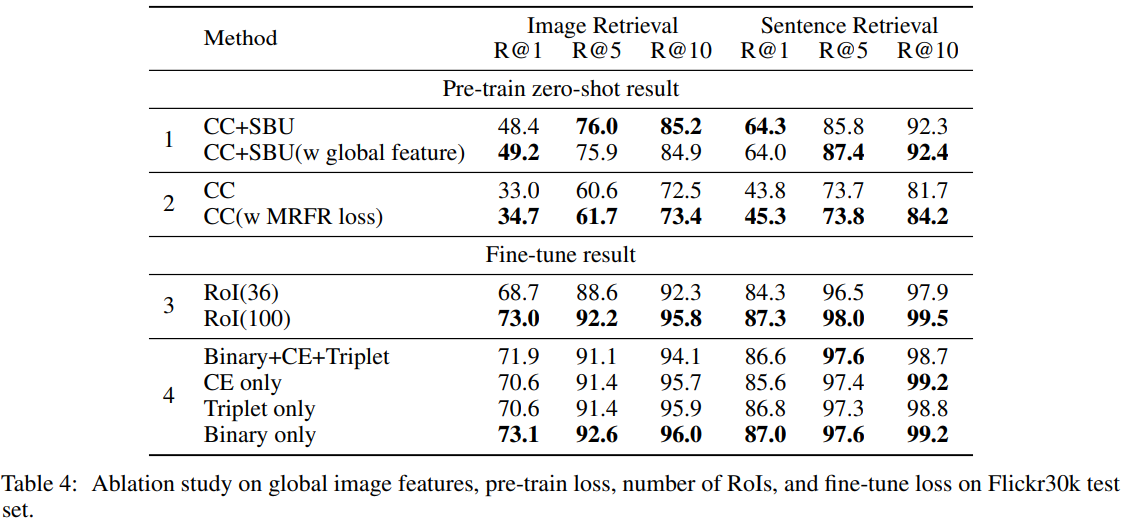
Global image features: RoIs가 전체 image의 정보를 담지 못 할때를 대비하여, Global image feature를 추가하는 방법을 실험하였습니다. Table4.1의 결과와 같이 유의미한 성능 개선은 보이지 않았습니다.
Pre-train loss: MRFR task를 유의미성을 Table4.2를 통해 보여줍니다. MRFR task는 다른 task보다 어려운 task에 속하는데, 이를 통해서 어려운 task를 추가하는 것이 더 좋은 model을 얻는데 도움이 된다는 것을 알 수 있습니다.
Number of objects (RoIs) from image: 지금까지 한 실험들은 모두 100개의 RoI를 사용하였습니다. RoI의 수가 성능에 미치는 영향을 Table4.3을 통해 보여줍니다. 많은 objects가 더 좋은 결과를 내는데 도움이 되는 걸 알 수 있습니다.
Fine-tune loss: Fine-tuning에 사용한 여러 loss의 결과를 Table4.4를 통해 보여줍니다. 개인적으로는 Triplet loss가 가장 좋을거라고 생각했습니다. 하지만 결과적으로 Binary only가 가장 좋은 결과를 보여줍니다.
6 Conclusion
이 논문의 특징을 정리하면, 아래 3가지로 요약할 수 있습니다.
- Transformer를 기반, vision-language joint embedding architecture
- 기존 data-set보다 큰 LAIT data-set
- Multi-stage pre-training with 4 tasks(MLM, MOC, MRFR, ITM)