dj-woo.github.io
I3D
리뷰할 Paper는 CVPR 2017에 나온, Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset입니다. action classification task에서 backbone으로 사용되는 I3D net을 제안합니다.
주요 contribution은 아래 2가지 입니다.
- Kinetics Human Action Video dataset을 사용하여, 더 많은 dataset을 사용한 transfer learning이 video task에서도 가능함을 보였습니다.
- new Two-Stream Inflated 3D ConvNet(I3D)을 제안 하였습니다.
1. Introduction
Image에서는 ImageNet dataset을 사용하여 model을 pre-train하고, 이를 다른 분야에 활용하는 transfer learning이 널리 사용되고 있습니다. 이러한 확장성이 video 분야에서는 가능한가?에서 논문을 시작하였습니다. 이를 실험하기 위해서는 video 분야에서도 큰 dataset이 있어야 하지만, 보통 10k정도의 dataset만 있어 이를 확인하기가 쉽지 않습니다.
그래서 기존 dataset보다 x100정도 되는 Kinetics Human Action Video Dataset(400 action class x min 400 clips)으로 실험을 진행하였습니다. Kinetics dataset으로 pre-training을 하고, HMDB-51 and UCF-101으로 fine-tuning을 하는 방식으로, 큰 dataset으로 pre-training을 하고, target dataset으로 fine-tuning을 하는 전략은 언제나 성능 향상을 보이는 것을 확인하였습니다. 하지만 그 성능 향상의 차이가 architecture에 따라 다르게 나타났고, 더 좋은 transferability를 보이는 “Two-Stream Inflated 3D ConvNets”(I3D)를 제안하여, SOTA를 달성하였습니다.
2. Action Classification Architecture
기존 work을 분석하기 위하여, video용 architecture는 아래와 같은 기준으로 분류 해놓았습니다.
- whether the convolution layer: 2D vs 3D
- how information is propagated: LSTM vs other feature affregation layer
- whether the input to the network: RGB vs +optical flow
위 분류 기준 + 제안하는 방법을 포함하여, 5가지 형태의 video architecture에 대해서 리뷰를 합니다.
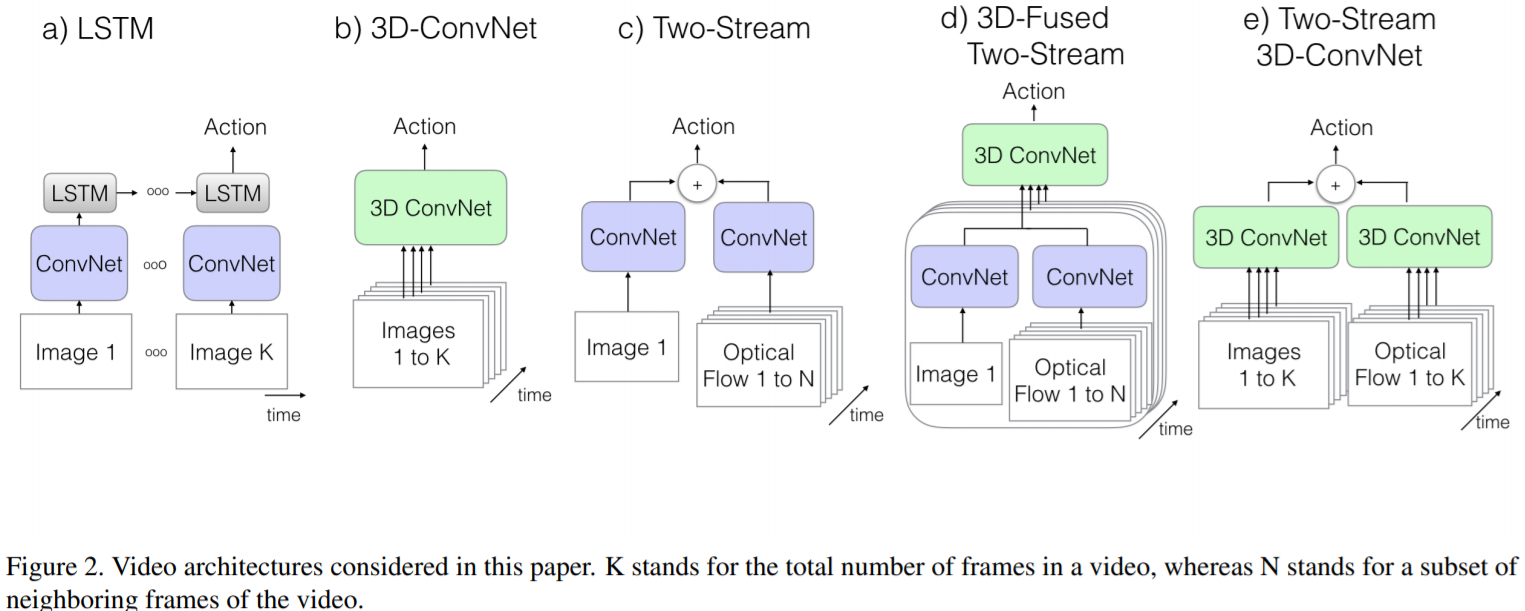
- The Old I: ConvNet+LSTM (a)
- 각각의 frame에서 feature 및 prediction을 추출 합니다.
- 각 frame의 prediction을 단순 pooling하여 video prediction을 뽑을 경우, 문의 여닫음 같은 temporal structure를 catch하기 어렵습니다.
- LSTM을 사용하여, 각 frame의 feature를 aggregation할 수 있습니다.
- 실험 조건
- cross-entropy losses on the outputs at all time steps
- use only the output on the last frame in testing
- 25fps input에서 5 frame만 sampling
- The Old II: 3D ConvNets (b)
- 가장 이상적인 approach로 볼 수 있습니다.
- 2D ConvNets에 비해, 엄청 늘어난 parameters로 train이 어렵다는 점이 단점입니다.
- 이전 논문들에서는 최대 8 layer 정도로 shallow net을 사용했습니다.
- 기존 image 기반 pre-trained되 2D ConvNets을 사용할 수 없는 점도 단점입니다.
- 실험 조건
- use 8 conv, 5 pool, 2 fully connected layers
- short 16-frame clips with 112 × 112-pixel crops
- The Old III: Two-Stream Networks (c,d)
- 2D ConvNet위에 LSTM을 올리는 방식은 high-level variation에는 유리하지만, fine low-level motion을 catch하는데 불리합니다.
- 이를 극복하귀 위하여, c)와 같이, 1장의 RGB와 전후 10장의 optical flow frame을 사용한 방법 입니다.
- 2개의 replica model을 사용하여, RGB image와 optical flows에 대한 prediction을 구합니다. 그후, averaging을 통하여 temporal snapshot의 prediction을 구하고, 학습합니다. (train time)
- test시에는 video에서 여러 multiple snapshot을 뽑아 이를 average하여 prediction을 구할 수 있습니다.
- 3D ConvNet을 사용하여 d)와 같은 구조로 확장할 수 있습니다.
논문에서 제안하는 Two-Stream Inflated 3D ConvNets(e)은 아래와 같은 특징을 가집니다.
- Inflating 2D ConvNets into 3D 기존 image classification architecture를 그대로 사용하기위해, 2D ConvNet의 filter와 pooling kernel을 inflating하여 3D ConvNet에 사용하였습니다.
- Bootstrapping 3D filters from 2D Filters Architecture를 그대로 모방하기 때문에, filter의 parameter도 재사용가능합니다. 이를 위해, 2D Filter의 parameter를 repeating(xN) + rescaling(/N)하여 사용합니다.
- Pacing receptive field growth in space, time and network depth 보통 image에서 receptive field는 가로, 세로 같은 크기를 가집니다. 하지만, time 방향 크기는 fps에 따라, 너무 크면 여러 object들이 뭉개질 수 있고, 너무 작으면 dynamic scene을 잘 capture하지 못할 수 있습니다. 본 논문에서는 실험적으로 나온 값을 pooling layer에 사용합니다.
- Two 3D Streams 3D ConvNet도 RGB image에서 motion feature를 추출할 수 있습니다. 하지만 실험적으로 optical flow를 같이 사용하는게 성능이 좋습니다. 같은 원리로, 2개의 3D ConvNet을 별도로 train하였고, 그들의 평균을 test time에 사용하였습니다.
아래 I3D net의 architecutre입니다. 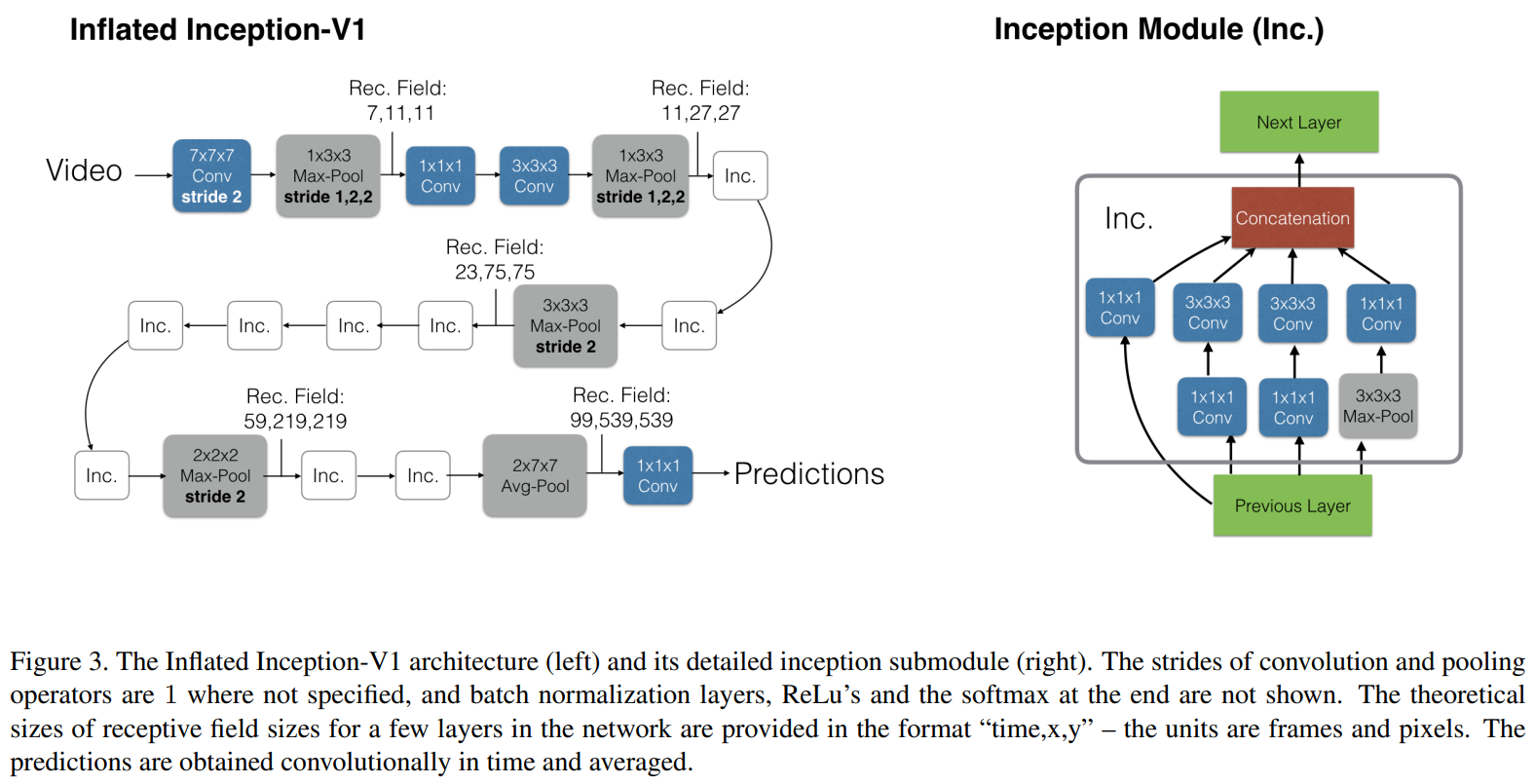 Input vedio의 size는
Input vedio의 size는 $1(batch)\times 64(frame)\times 224(H)\times 224(W)\times 3(C)$을 사용합니다.
최종 output은 $1 \times 4 \times 1 \times 1 \times [logits]$가 되고, axis=1로 average하여, 최종 softmax에 들어가 prediction을 하게 됩니다.
Implementation Details
- standard SGD with momentum set to 0.9
- trained models on on Kinetics for 110k steps, with a 10x reduction of learning rate when validation loss saturated
- trained for up to 5k steps on UCF-101 and HMDB-51 using a similar learning rate adaptation procedure as for Kinetics
- computed optical flow with a TV-L1 algorithm
- Data
- used random cropping
- spatially: resizing the smaller video side to 256 pixels, then randomly cropping a 224 × 224 patch – temporally: when picking the starting frame among those early enough to guarantee a desired number of frames
- For shorter videos, looped the video as many times as necessary to satisfy each model’s input interface
- applied random left-right flipping consistently for each video during training
- used random cropping
- Test
- 224 × 224 center crops
- the predictions are averaged
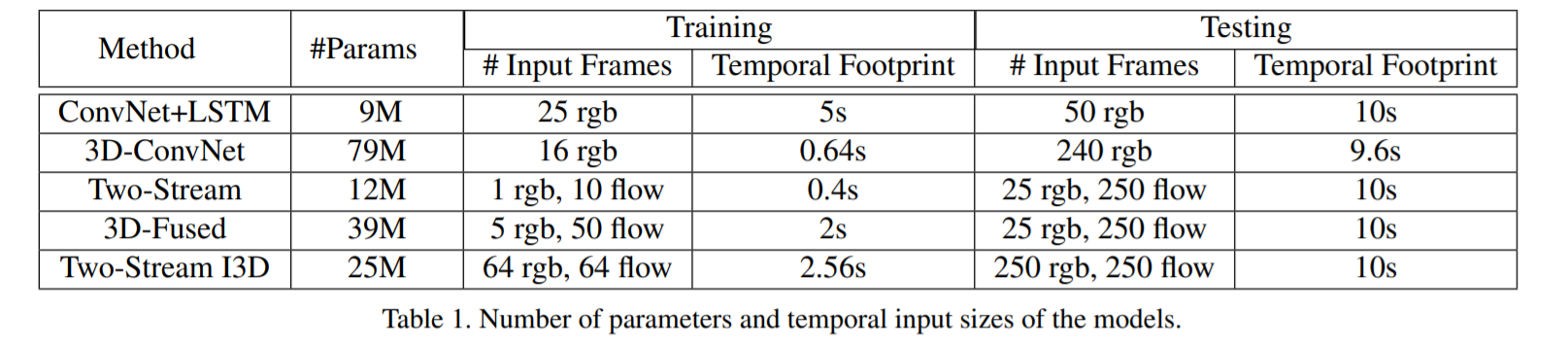
3. The Kinetics Human Action Video Dataset
Kinetics dataset은 human action에 focuse를 두고 만들어진 dataset입니다. 수영 종목과 같이 fine grain & temporal reasoning이 필요한 class도 있고, object에 중점을 둔 class도 있습니다.
2020년에, 700 class x 700 clips 버전인 Kinetics-700까지 나와 있습니다.
- 400개의 human action class
- minimal 400 clips per class
- training set: 240K
- test set: 100 clips per class
다른 dataset과 간단히 비교하면 아래와 같습니다.
- UCF-101: 101 action classes, over 13k clips and 27 hours of video data
- HMDB-51: About 2GB for a total of 7,000 clips distributed in 51 action classes
4. Experimental Comparison of Architecture
가장 먼저, 3개의 dataset에서 5가지 architecture의 성능을 비교합니다. test에서는 3D-ConvNet을 제외하고, ImageNet으로 pre-trained된 Inception-v1이 사용되었습니다. 실험을 통해 알 수 있는 점은 아래와 같습니다.
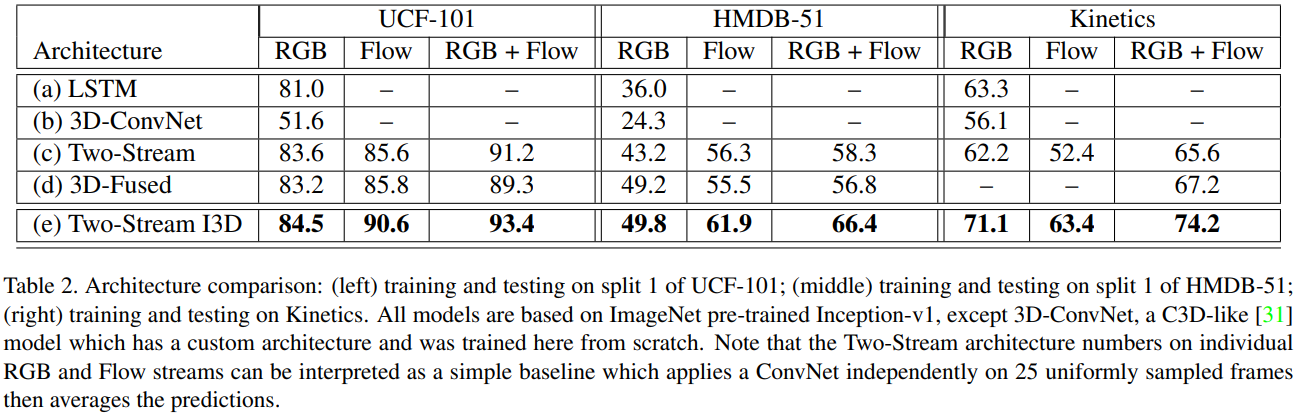
- ImageNet pre-training이 3D로도 확장 가능 상대적으로 parameter(25M)가 많은 I3D가 작은 dataset인 UCF-101, HMDB-51에서도 좋은 성능을 보여주고 있습니다. 반면에, pre-trained Inception-v1을 사용하지 못한 3D-ConvNet(79M)은 가장 안 좋은 결과를 보여줍니다.
- Dataset간 난이도 차이가 있음 모든 architecture의 성능이 UCF-101 > Kinetics > HMDB-51 순으로 나타납니다. 이는 dataset간 난이도 차이로 해석할 수 있습니다.
- Architecture의 성능 순위는 모든 dataset에서 대체로 유사함.
- RGB+Flow가 RGB, Flow 단독보다 더 좋은 성능을 보임 다른 architecutre들은 Flow only가 RGB only보다 좋은 성능을 보입니다. 하지만, I3D에서는 RGB의 성능이 더 좋습니다. 이를 I3D의 receptive field가 더 크기 때문에, Flow only에는 안 좋은 영향을 주었다고 분석하였습니다. 실제로, Flow network filter와 RGB network filter를 학습 후 비교해보면, Flow network filter는 기존 pre-trained된 filter와 비슷한 모습을 보이지만, RGB network filter는 더 다양한 양상을 보여줍니다.
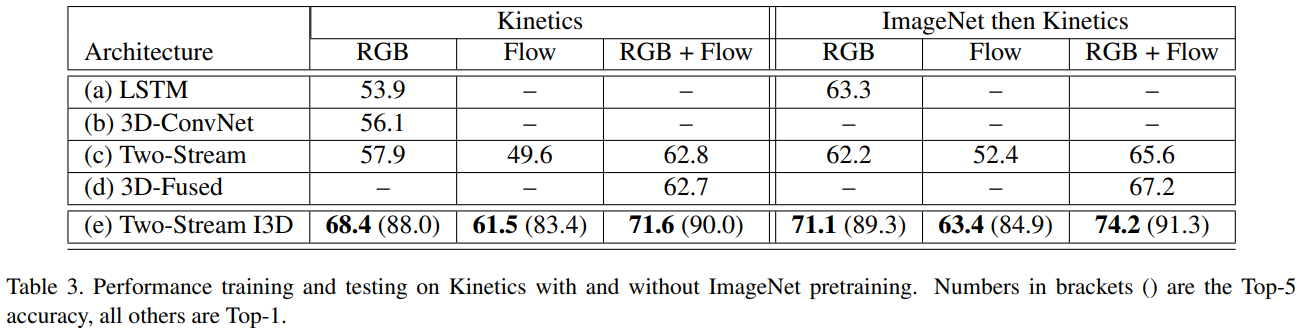
- ImageNet으로 pre-trained된 weight를 이용하는 것이 더 좋은 성능을 보여줍니다.
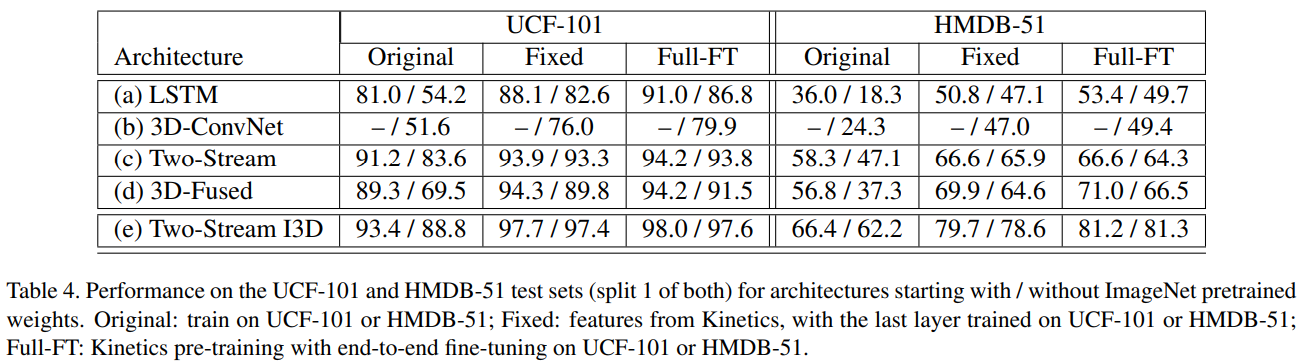
large dataset인 Kinetics로 pre-training을 진행하여, transfer learning이 잘되는지를 보여주는 실험입니다.
- 모든 architecture에서 Kinetics를 사용한, Fixed와 Full-FT가 Original에 비해 더 좋은 성능을 보여줍니다.
- 특히 3D-ConvNet과 I3D에서 더 좋은 성능을 보여준다고 되어 있습니다.
- 개인적으로 3D-ConvNet은 이해가 되지만, I3D는 어느 data에서 더 좋은 transfer learning을 보여 줬다는 건지 잘 모르겠습니다.
- I3D의 transferability가 높은 이유는 video imange를 sampling하지 않고, 바로 사용하기 때문이라고 분석 하였습니다.
추가적으로 이전 SOTA work과 비교를 하여, I3D가 UCF-101, HMDB-51에서 I3D가 모두 좋은 성과를 보여주는 것을 확인했습니다.
Discussion
“is there a benefit in transfer learning from videos?”에 대한 대답은 considerable benefit이 있다라고 결론 짓습니다. 하지만, pre-training과 다른 task에서도 benefit이 있는지에 대해서는 추가 실험이 필요하다고 나와있습니다.