Torch_tutorials
개인 study를 위한 자료입니다.
그러다보니 내용에 잘못된 점이 있습니다.
PyTorch tutorial 을 하면서, 이해한 내용을 정리를 하였습니다.
Summary
torch.tensor- “N차원 배열 data” + “GPU” + “gradient”- N차원 배열 data를 저장하는 면에서,
numpy.ndarray와 비슷합니다. - CPU/GPU device 이동을 지원합니다.
to(device) autograd를 지원합니다. 이를 통해, back propagation을 손쉽게 할 수 있습니다.
- N차원 배열 data를 저장하는 면에서,
torch.nn- Neural Networks을 정의합니다.Module: Layer와forwardmethod를 포함하며, 주로 model를 새로 정의할때, parent class 로 사용합니다.Parameter: Tensor의 subclass(wrapper)로,Module에서 학습을 위한 weight 관리를 용이하게 합니다.parameters()iterator 로 불러 올 수 있습니다.functional: 활성화 함수, 손실 함수 등을 포함하는 모듈로 일반적으로Fimport합니다. 또한 convolution과 linear layer와 같이, 저장 state를 가지는 layer의 non-statefule 버전 레이어도 포함되어 있습니다.
torch.optim-backward()단계에서,Parameter를 update하는 optimizer를 포함하는 moduleDataset- dataset을 표현하기 위해 제공되는__len__과__getitem__을 포함하는 abstract class.DataLoader-Dataset을 기반으로 데이터의 배치를 출력하는 iterator.
1. torch.Tensor
numpy.ndarray와 비슷하게 다차원 연산을 위한 기본 function들을 제공합니다.
그리고, PyTorch는 tensor에 autograd를 넣어 가장 중심이되는 class로 사용합니다.
- 이전에는
torch.autograd.Variable이라는 tensor의 wrapper class가 있어, 여기서 operation hisotry를 저장했습니다. 하지만,autograd가tensor에서 자동 지원되면서, 더 이상 지원하지 않습니다.)
torch.Tensor is the central class of the package.
tensor.requires_grad를 True로 하면, tensor를 사용한 연산과정을 기록(grad_fn)합니다.
그리고, 최종단 tensor에서 .backward()가 수행되면, gradient가 계산되어 tensor.grad에 저장되고,
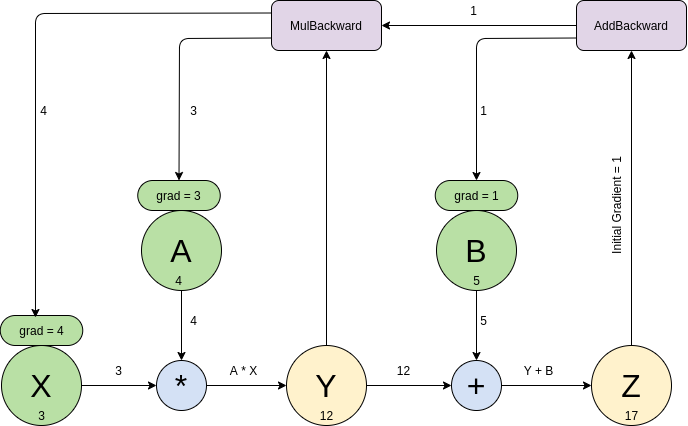
이 값은, grad_fn에 기록된 연산을 타고, back propagation 이 진행됩니다. 예를 들어 아래와 같이 code를 작성한 경우 [2],
아래 그림과 같은 NN이 생성이 되며, z와 y는 gard_fn에, 해당 tensor가 계산 되는 과정이 저장됩니다.
z.backward()가 수행이되면, z.grand_fn에서 주어진 값들이 back propagation 되면서,
x.grad, a.grad, b.grad가 자동 계산됩니다.
이 기능을 통해서, tensor 만으로도 model 작성과 학습이 가능합니다.
2. torch.nn & torch.optim & Dataset & DataLoader
이 부분은 실제 예제를 통해서 이해하는게 좋습니다.[3]
torch.nn, torch.optim, Dataset 그리고 DataLoader없이 Tensor만을 이용해서, 아래와 같이 Linear regression을 model을 구현하고 학습할 수 있습니다.
1) nn.functional 사용
여기서, torch.nn.functional를 사용해서, log_softmax() + negative_log_likelihood()를 하나의 함수로 처리할 수 있습니다.
2) nn.Module 사용
학습의 대상이 되는 parameter와 Neural Networks model을 쉽게 관리하기 위하여, nn.Module을 사용합니다.
nn.Module의 Parameters()를 이용해서, model에 속해 있는 parameter에 대해서 아래와 같이 쉽게 관리 할 수 있습니다.
3) nn.Linear 사용
미리 정의된 Model들 을 사용해서, code를 리팩토링 할 수 있습니다.
nn.Linear를 사용해서, self.weights와 self.bias의 정의와 초기화 작업 그리고 xb @ self.weights + self.bias 계산을 대신 할 수 있습니다.
4) optim 사용
미리 구현된, optimization 알고리즘을 torch.optim을 이용하여 사용할 수 있습니다.
이를 통해, parameters를 step() method를 사용하 update할 수 있습니다.
5) Dataset & DataLoader 사용
구현을 하다보면, data를 load하고 자르고 섞는데 많은 code가 들어 갑니다.
이때, Dataset과 DataLoader를 사용하면 이 부분을 쉽게 구현할 수 있습니다.
__len__과 __getitem__를 가진 class는 Dataset으로 사용할 수 있습니다.
반대로 __len__과 __getitem__만 만들면, customize된 Dataset을 정의할 수 있습니다.
Tensor를 입력으로 받는 경우, 미리 정의된 TensorDataset를 사용할 수 있다.
DataLoader는 batch 관리를 담당합니다.
Dataset과 DataLoader를 사용하면 아래와 같이 코드가 훨씬 깔끔해 집니다.
6) 최종 code
torch.nn & torch.optim & Dataset & DataLoader를 사용하여, 아래와 같이 code를 refactoring 할 수 있습니다.
